ExoPredicator: Abstracting Time and State for Robot Planning

For an AI to understand and act in a new environment, does it need to reason about every detail at every moment? That would be intractable, and it is not how humans plan their days, weeks, or even hours. Instead, we abstract, skipping irrelevant details and reasoning at whatever granularity the task requires.
For example, when we plan an international trip, we reason about border crossings and layovers without considering the color of the airplane or the exact milliseconds of takeoff. Similarly, when we learn to use a new kitchen appliance, we figure out what each button does without pinning down the exact dynamics of blending. The same goes for picking up a new video game, learning an unfamiliar app, or figuring out a new power tool: starting from general-purpose motor skills and perception abilities, we quickly figure out the essentials of how something works, and use this imprecise mental model to make good decisions fast.
We take a step toward endowing AI systems with these capabilities in our ICLR 2026 paper introducing ExoPredicator, an algorithm that assembles approximate, abstract world models.1 This involves state abstraction, like learning that airplane color is irrelevant to planning a trip. It also involves temporal abstraction, like learning that turning on a faucet eventually spills water, without modeling the exact physics of water flow. ExoPredicator also learns to model exogenous processes (things the environment does on its own), enabling the robot to anticipate, multitask, and plan around dynamics it doesn’t directly control.
ExoPredicator builds on our earlier work, VisualPredicator, which introduced the idea of learning neuro-symbolic predicates (short Python programs that can query vision-language models) and using them for robot task planning.2 VisualPredicator showed that a robot could learn useful state abstractions from limited interaction, but it assumed all effects were instantaneous and deterministic, with no model of what the environment does on its own. ExoPredicator extends this line of work to handle the temporal and causal richness of dynamic environments: it learns not just which features matter, but how they evolve over time and respond to both the robot’s actions and the environment’s own dynamics.
Learning an abstract causal model of the world through program synthesis has three benefits, shown in the simulated robot environments below:
- Efficient learning of how new environments work, from limited interaction
- Fast reasoning for achieving new goals, by planning over the learned abstraction
- Interpretability of the learned world model, since it is expressed as human-readable code
In what follows, we explain how ExoPredicator represents its abstract causal models of the world, and how representing them as programs facilitates fast learning and reasoning.
How ExoPredicator models the world
ExoPredicator abstracts the world state using learned predicates: short Python programs that query a vision-language model to check whether some abstract feature holds in the current scene, such as whether a jug is full or a burner is on. Instead of planning over raw images or dense embeddings, the robot plans over compact symbolic descriptions.
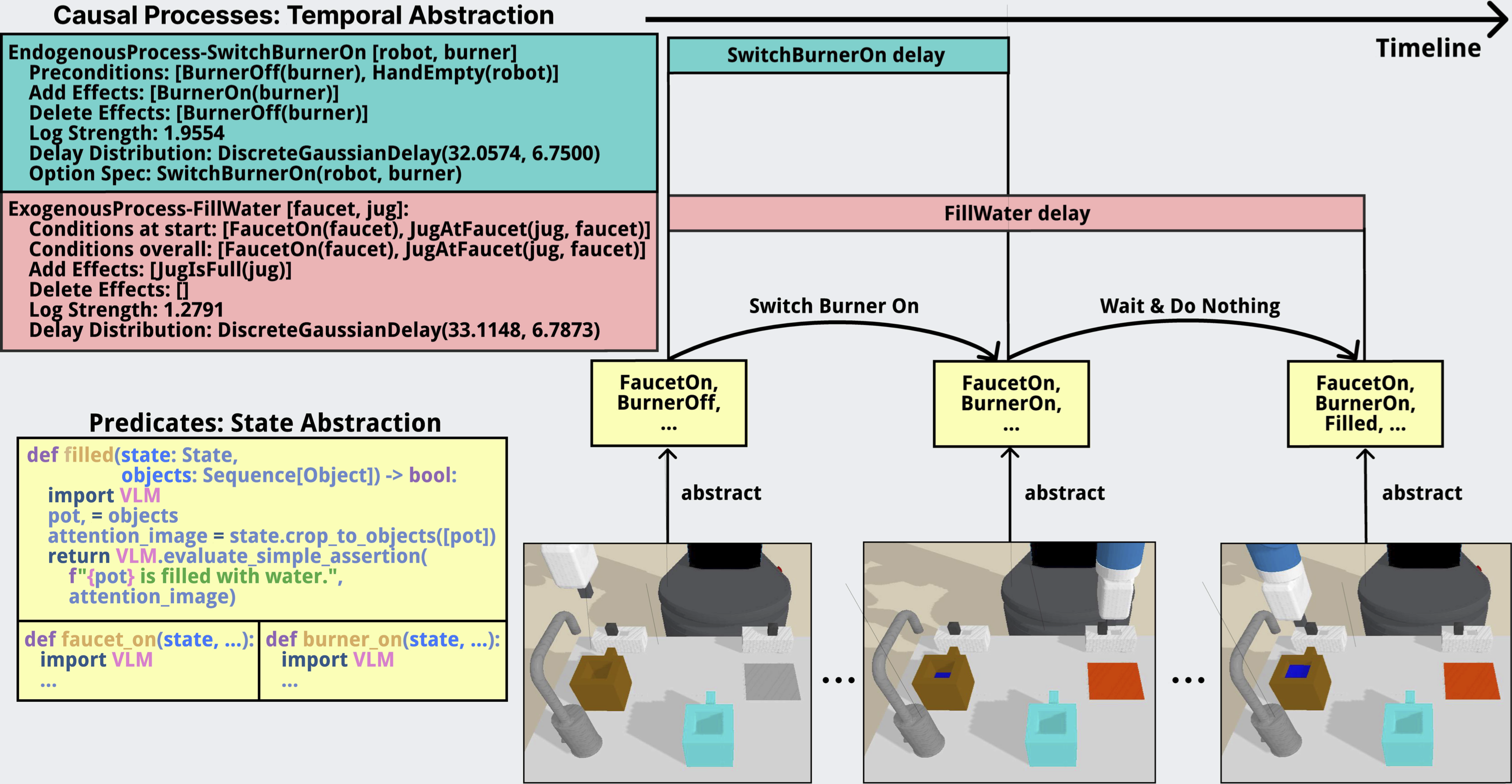
To learn an abstract world model, we also need to capture how predicates change over time. Switching on a burner causes immediate heat, which gradually causes water to warm, which eventually causes it to boil. Turning on a faucet causes water flow, which eventually either makes a mess or fills a pot. Topple the first domino, and the rest fall.
We capture these dynamics with causal processes: structured rules (declarative programs) that describe the conditions under which a past cause triggers a future effect, along with a probability and a delay distribution. Causal processes are natively probabilistic, and are meant to model the world coarsely and abstractly. We find it helpful to distinguish two kinds of causal processes: Endogenous processes model the robot’s own actions, like picking up an object or switching on a faucet. Exogenous processes model the environment’s own dynamics, like coffee filling a cup, water boiling on a burner, a domino cascade propagating, or a fan pushing a ball through a maze.
This representation lets the planner reason at the right level of abstraction. Rather than stepping through every fine-grained transition, ExoPredicator jumps between abstract states. Because it models exogenous processes explicitly, it can multitask. For example, the robot can switch on a faucet to fill a jug and walk away to start the burner, because it knows the filling will proceed on its own and that it has enough time to come back before the jug overflows. Sometimes the right move is to wait.
Learning how the outside world works
The robot is not assumed to start from nothing: it has built-in motor skills and a few basic predicates tied to its own body (e.g., whether it is holding an object), along with models of endogenous processes for its own actions like Pick and Place. What it needs to learn is everything else: which perceptual distinctions matter, which exogenous processes govern what happens next, and how those effects unfold over time.
Learning is online. The robot plans with its current model, acts in the environment, and updates the model based on what happens. It learns from failures: when a plan fails, something in the model is wrong or missing, and the system responds by proposing new predicates and searching for causal processes it has not yet discovered. Under the hood, it performs Bayesian model selection over candidate symbolic structures (new predicates, new processes) proposed by language-model-guided program synthesis. Variational inference both computes marginal likelihoods for model selection and tunes probabilistic parameters (delay distributions, effect probabilities). It needs little data because it draws on LLM code priors and Bayesian model selection. We aim for reliable decision-making from little data, not perfect prediction.
We evaluate across five simulated tabletop environments. In Coffee, the robot works around filling and pouring. In Grow, it discovers plants only grow when watered by a matching-color jug. In Boil, it manages a faucet and burner without overspilling. In Domino, it reasons about cascades and recognizes impossible tasks. In Fan, it routes a ball through a maze using fans.
ExoPredicator learns one to four exogenous processes per domain, converges within three learning iterations, and solves nearly all tasks in Coffee, Domino, and Fan, and over 80% in Boil and Grow. In several domains, the learned abstractions match or even outperform manually engineered ones; variational inference tunes delay distributions and process parameters more precisely than hand-specified values.
A robot can learn a planning model that is compact enough to plan efficiently, but rich enough to handle delayed, concurrent, uncertain dynamics.
Where ExoPredicator sits among other approaches
Several other families of approaches tackle related problems, each with different trade-offs.
Task and motion planning (TAMP) integrates high-level action selection with low-level geometric reasoning, but typically requires manually engineered symbolic models and does not represent exogenous processes: it reasons about how actions affect the world, but not what the world does on its own.3 ExoPredicator learns its models from data and explicitly handles both endogenous and exogenous dynamics. In our experiments, STRIPS-style operator learners that try to fit exogenous dynamics into a standard action framework struggle because they cannot represent varying delays or preconditions that fall outside the action’s own variables.
VLM planning prompts a vision-language model directly to select a sequence of skills. In our experiments, we test a baseline that prompts Gemini-2.5-Pro to plan over the available skills. It works well in simple domains where the right plan resembles the demonstration (e.g., in Coffee, the plan is mostly just repeating Pour and NoOp). But it struggles in domains that require discovering novel rules through trial and error (like color-matching in Grow) or composing skills in new ways. Without a learned world model specific to the environment, the VLM struggles to reason about exogenous dynamics, like how long water takes to boil or how a domino cascade propagates, making it hard to plan around them.
JEPA-style world models like V-JEPA 2 learn abstract representations and predict future states in representation space rather than pixel space — an idea ExoPredicator shares.4 Both approaches learn latent world models that discard irrelevant detail. But where JEPA predicts the next latent state frame-by-frame using a self-supervised objective, ExoPredicator is closer in spirit to Hierarchical JEPA:5 it abstracts over time, jumping between meaningful abstract states via causal processes with learned delays, rather than stepping through every timestep. The other key difference is how the models are learned: ExoPredicator uses Bayesian inference and program synthesis rather than gradient-based self-supervised learning, producing interpretable symbolic models that a planner can directly search over.
Video world models like Cosmos and Genie generate rich future observations at scale.67 But most of this detail is unnecessary for planning, and their low-level, frame-by-frame nature makes them insufficient for long-horizon reasoning. ExoPredicator instead discovers the minimal causal structure needed for decision-making: sparse and task-relevant rather than generatively broad.
Vision-language-action models like π-0.5 learn generalizable policies end-to-end from large-scale heterogeneous data.8 They address a different problem: given enough demonstrations, learn a policy that transfers broadly. ExoPredicator instead learns a world model from limited interaction in a specific environment, so a robot can plan for new goals by reasoning over how that environment works. The two approaches are complementary — a VLA could provide the low-level skills that ExoPredicator plans over.
Limitations and what’s next
ExoPredicator works well in our five tabletop domains, but there is plenty of room to grow.
Richer logical structure. In the Boil domain, ExoPredicator fails to learn the full disjunctive condition for water spilling: it learns that spilling happens when there is no jug under the faucet, but misses the case where the jug underneath is already full. Supporting richer logical conditions (disjunctions, counting, relational constraints) in learned processes would expand what the system can capture.
More complex environments. Our current experiments use simulated tabletop settings with a handful of objects and skills. Scaling to environments with more objects, longer horizons, and richer interactions (e.g., a full kitchen, a workshop, or multi-room navigation) will test whether the framework’s abstractions remain tractable and useful.
Learning skills alongside world models. Right now ExoPredicator assumes a fixed set of motor skills (Pick, Place, Push, etc.) and learns the world model on top. An exciting direction is to learn new skills and world models jointly: as the robot discovers new causal structure in the environment, it could also learn new ways to interact with it.
Tighter integration with foundation models. We currently use LLMs to propose candidate predicates and process structures, then score them with Bayesian model selection. Foundation models could play a larger role: using vision-language models not just for predicate evaluation but for richer scene understanding, or using LLM reasoning to guide exploration and hypothesis generation more tightly.
We showed that a robot can learn abstract causal models from limited data and use them to plan effectively. We’re excited about where this line of work goes next.
References
Y. Liang, D. Nguyen, C. Yang, T. Li, J. B. Tenenbaum, C. E. Rasmussen, A. Weller, Z. Tavares, T. Silver, and K. Ellis, “ExoPredicator: Learning Abstract Models of Dynamic Worlds for Robot Planning,” ICLR 2026. ↩︎
Y. Liang, N. Kumar, H. Tang, A. Weller, J. B. Tenenbaum, T. Silver, J. F. Henriques, and K. Ellis, “VisualPredicator: Learning Abstract World Models with Neuro-Symbolic Predicates for Robot Planning,” ICLR 2025. ↩︎
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano-Pérez, “Integrated Task and Motion Planning,” Annual Review of Control, Robotics, and Autonomous Systems, vol. 4, pp. 265–293, 2021. ↩︎
M. Assran et al., “V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning,” 2025. ↩︎
Y. LeCun, “A Path Towards Autonomous Machine Intelligence,” 2022. ↩︎
NVIDIA, “Cosmos World Foundation Model Platform for Physical AI,” 2025. ↩︎
J. Bruce et al., “Genie: Generative Interactive Environments,” ICML 2024. ↩︎
K. Black et al., “π0.5: a Vision-Language-Action Model with Open-World Generalization,” 2025. ↩︎