AutumnBench: World Model Learning in Humans and AI
July 17, 2025
Introduction
When you first encounter a new device—be it a smartphone, kitchen appliance, or unfamiliar video game—you rapidly build an intuitive mental model of how it works. Within minutes, you can predict its behavior, imagine different scenarios, and plan effective actions. This ability to quickly and flexibly construct world models is fundamental to human reasoning, enabling us to anticipate the future, reconstruct past events, and consider counterfactual “what-if” questions.
Despite the increasing recognition that both having and discovering world models are central to intelligence, current AI systems struggle to replicate this human capability. There remains significant uncertainty about what precisely constitutes a world model, how we might reliably detect if an agent possesses one, and crucially, how we can develop agents that learn these models rapidly and reliably.
To bridge this gap, we introduce AutumnBench, an interactive benchmark explicitly designed to evaluate and accelerate progress in AI systems’ capacity for adaptive world modeling through exploration and experimentation. AutumnBench exposes agents—whether human or artificial—to a series of dynamic, interactive environments, each encoded within a simple 2D grid but featuring diverse mechanisms, including causal interactions, hidden constraints, and evolving states. Unlike traditional reinforcement learning settings, these environments do not provide explicit rewards. Instead, agents must actively experiment, driven solely by curiosity and intrinsic motivation, to discover how each world operates.
This benchmark marks the second major release from Project MARA, following our earlier ARC-focused transduction-induction model. MARA’s overarching goal is to uncover principled methods for how intelligence constructs, refines, and utilizes world models through interactive experimentation.
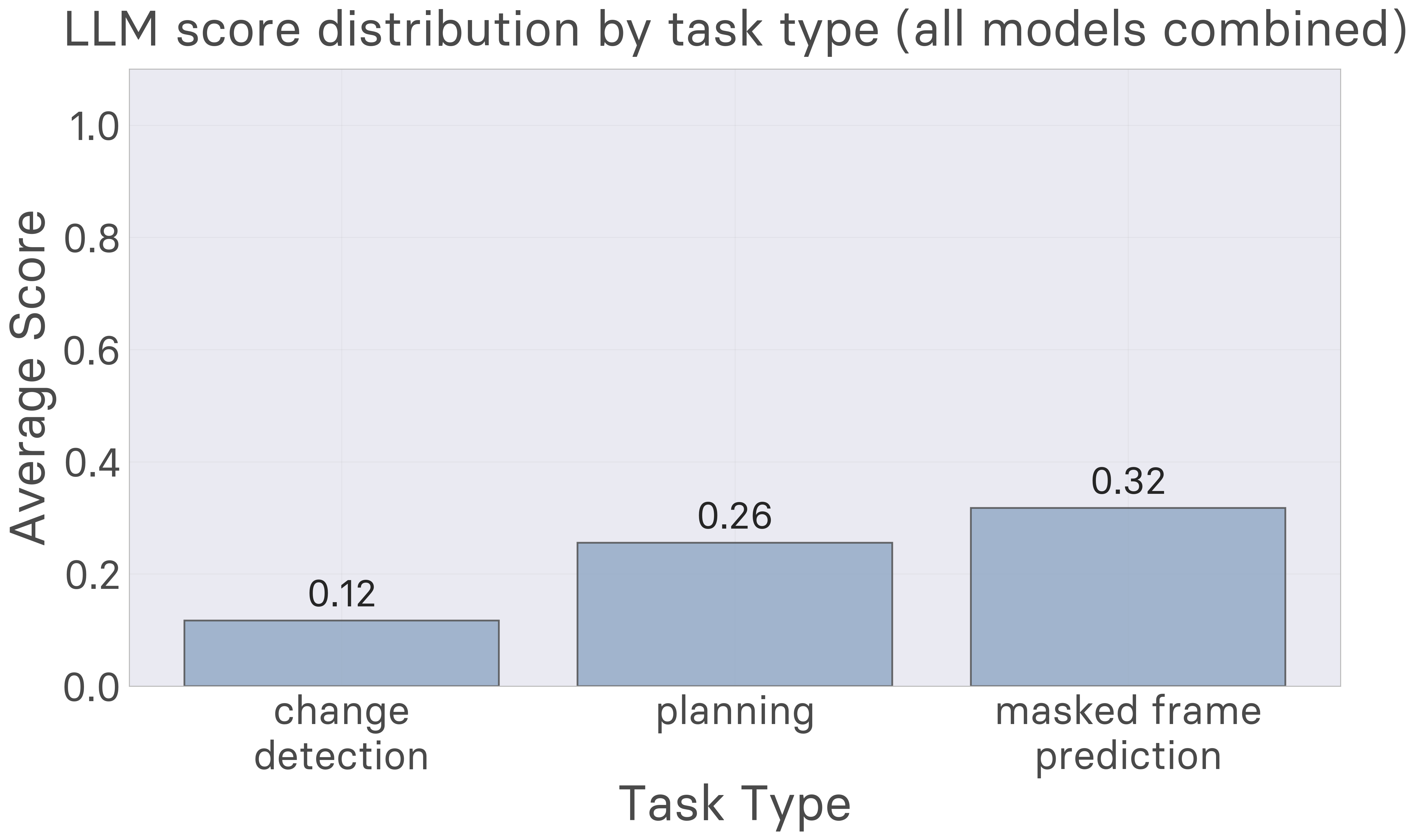
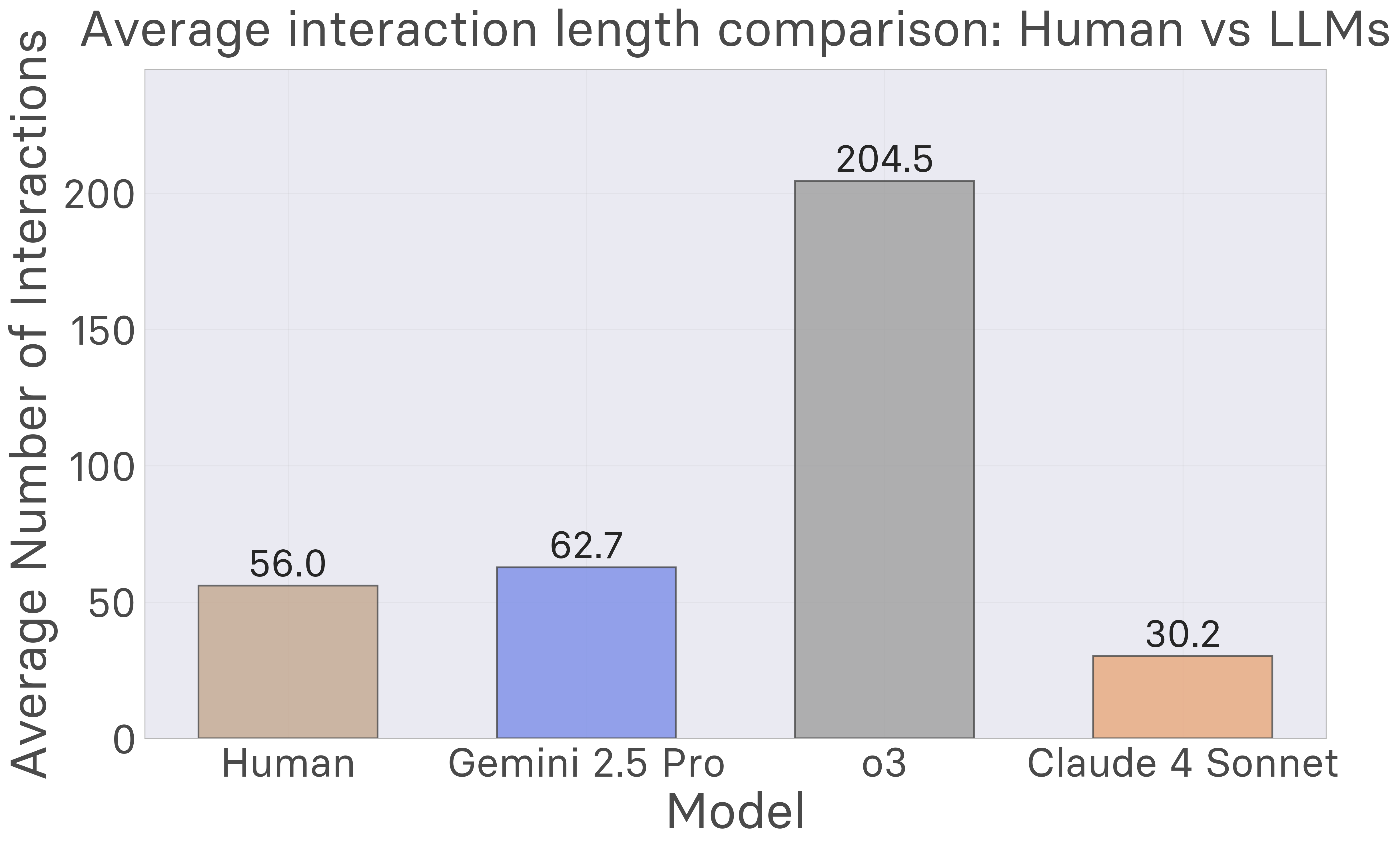
Initial experiments conducted by the MARA team with 517 human participants and multiple frontier AI models reveal striking performance differences. Humans achieve an average score of 1.86 out of 5 across 2585 task attempts—well above chance but far from perfect, with only 1.2% achieving perfect scores. Remarkably, humans demonstrate rapid learning, typically requiring just 40-60 interactions over about one minute to build effective world models. In contrast, current large language models including Claude 4 Sonnet, Gemini 2.5 Pro, and o3 consistently underperform humans across all task types, with particularly severe deficits in planning and change detection tasks. These results highlight a fundamental gap in existing AI capabilities, yet they also suggest a clear path toward improvement: AI systems must become proficient at rapidly constructing flexible world models through exploration, as humans naturally do.
AutumnBench serves a dual purpose: it is both an AI benchmark aimed at catalyzing the development of AI systems that truly learn models of the world, and a cognitive science platform offering insights into the human capacity for building and updating mental models of novel environments. Rather than requiring that a world model has a specific representation, AutumnBench defines success in terms of the ability to answer questions that require understanding of causality, prediction, and inference, allowing various AI methodologies—neural, symbolic, or hybrid—to participate meaningfully.
Ultimately, MARA aims to build AI systems capable of everyday “intuitive science”—the model-building and exploratory reasoning humans naturally engage in when encountering new environments, tools, or concepts. AutumnBench formalizes this ambition, sets a clear benchmark for progress, and invites researchers to tackle one of the defining challenges in artificial intelligence.
Learning and using world models
Each environment in AutumnBench is a different world with its own physics, programmed in Autumn, a self-contained domain-specific programming language we designed to specify these domains. Experimenting in a new environment works by clicking and pressing arrow keys while observing how the environment reacts in real time. Environments can be viewed as simple videogames, but unlike most videogames, there is no winning or losing—the goal is to experiment enough to understand how the world works.
Assessing World Models
How should we test whether an agent has discovered a good model of its environment? Previous work on Autumn (blogpost and paper) built a system that outputted source code. This made evaluation simple, since the ground-truth world was in Autumn and the discovered model was in Autumn, too. But this commits a system to a specific symbolic representation, limiting what it can learn, and burdens it with the task of recovering a perfect model that captures every minutiae of the world—an impossible task in most environments. Another approach, which is standard in the machine learning community, is to say that an agent has learned a world model if it can perfectly predict future observations. Testing whether we can predict the next observation is powerful, because it means the AI system can perfectly simulate the world. But pixel-perfect prediction is too demanding: Reasoning tasks such as planning do not require a perfect simulation, and humans can reason abstractly without committing to perceptual-level details: e.g., scientific theories such as Kepler’s Laws or evolution by natural selection do not predict every perceived detail of the natural world, but instead describe more abstract regularities.
In AutumnBench we therefore take a different approach, based on the conceptual foundation that a world model should support many forms of reasoning. We use a collection of different kinds of tests, none of which require perfectly predicting the next observation. Each test occurs after the free-experimentation phase. We view these tests as an open set that will grow over time, but currently we have three:
- Masked Observation Prediction with Multiple Choice. A pre-recorded masked video, i.e., a sequence of observations and actions, of someone else interacting with the environment is presented to the agent. However, a region of the image is masked over some duration of time. The agent is tasked with predicting the final state of the masked region, choosing from 6 different multiple choice options.
- Planning. A target goal state is provided, and then the system interacts with the environment to drive it into that state. This tests whether its understanding of the world can be used for planning and goal-directed behavior. During the experimentation phase, no goal is provided, so its understanding of the world must be robust enough to cover a broad range of possible goals.
- Change Detection. The agent is put back in the same environment, but the underlying dynamics of the environment will change at some point. The task is to predict when the dynamics changed. Understanding when the world changes is important for dealing with nonstationary environments.
Each of these tests is designed so that an agent with a perfect world model and perfect reasoning should in principle be able to answer every question perfectly and unambiguously.
Try the experiment right now yourself at autumn.basis.ai.
Human Performance and Analysis
517 human participants completed AutumnBench tasks on Prolific, generating 2585 task data points across our three evaluation types. We find the following:
- Humans can do these tasks, but remain far below ceiling. People are well above chance across all three types of test, but unlike benchmarks that aim to be ’easy for humans, hard for AI’, AutumnBench has a broader spectrum of difficulty: Some environments are trivial for people, while others are intended as challenges. Therefore, an important future goal is not just matching human performance, but outperforming even the best humans, which we see as the right target for an AI scientist.
- Masked frame prediction is not a prerequisite for other world-modeling tasks. The canonical world modeling task is to predict future observations. Even when human participants cannot reliably predict what will happen next, they still succeed at planning to achieve novel goals, and at detecting changes in the underlying dynamics. This suggests that they possess partial world models that do not perfectly predict the future, but which can still be used for a variety of reasoning problems.
- Human learning is rapid, from tens to hundreds of environment interactions. World model learning is neither few-shot nor big-data. People interact with each environment for about a minute, making 40-60 actions, and calibrate the amount of experimentation to the downstream task: For planning tasks which allow further interaction during testing, people interact less during the experimentation phase, compared to when they expect to predict future observations or detect when environment dynamics change.
Detailed Human Performance Analysis
Our analysis further reveals:
Performance Statistics: With an average score of 1.86 ± 1.25 out of 5, humans are well above chance but far from perfect. Only 6 participants (1.2%) achieved perfect scores, while the median performance was 1.85. This confirms AutumnBench’s design as having a broader spectrum of difficulty rather than being trivially easy for humans.
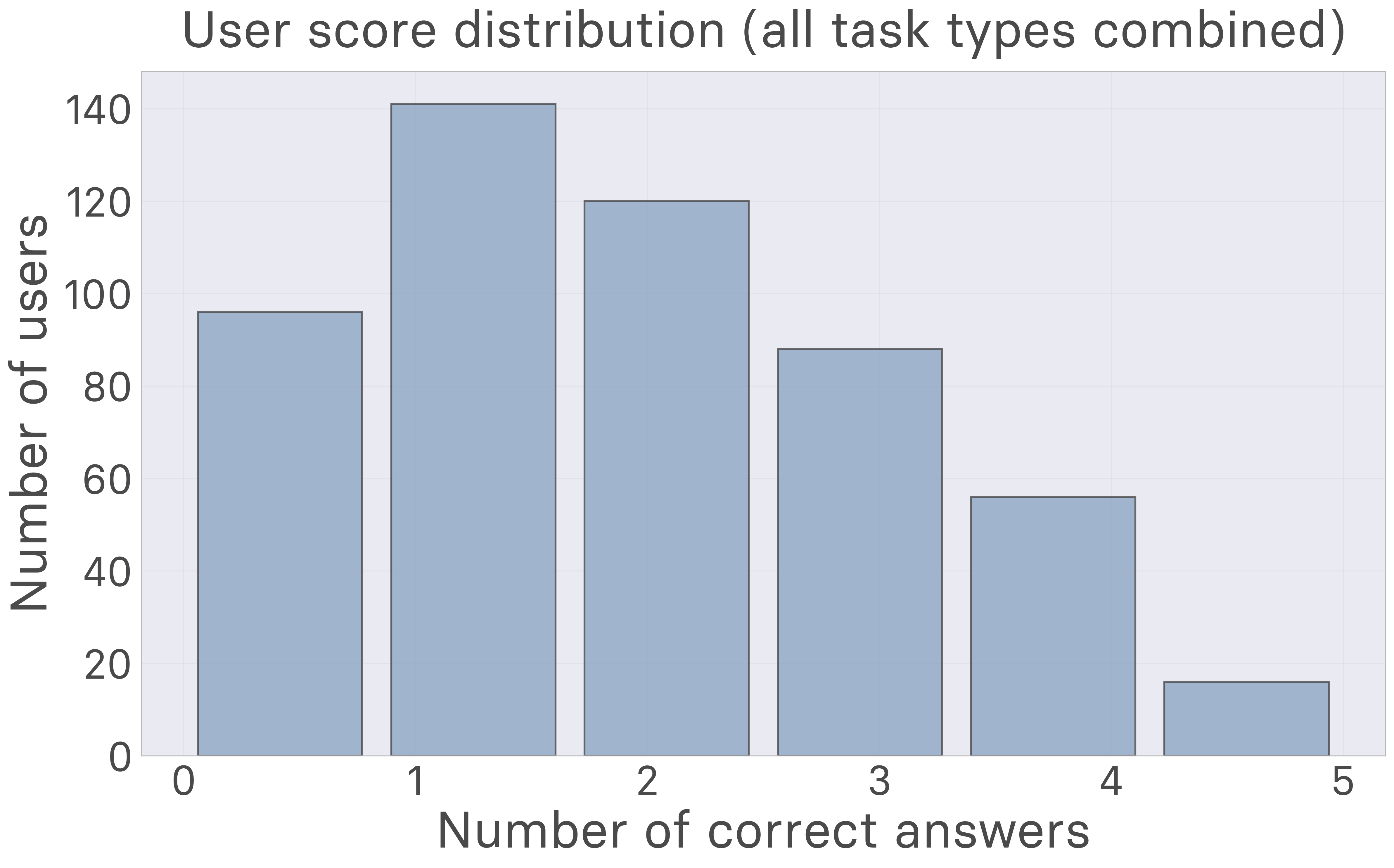
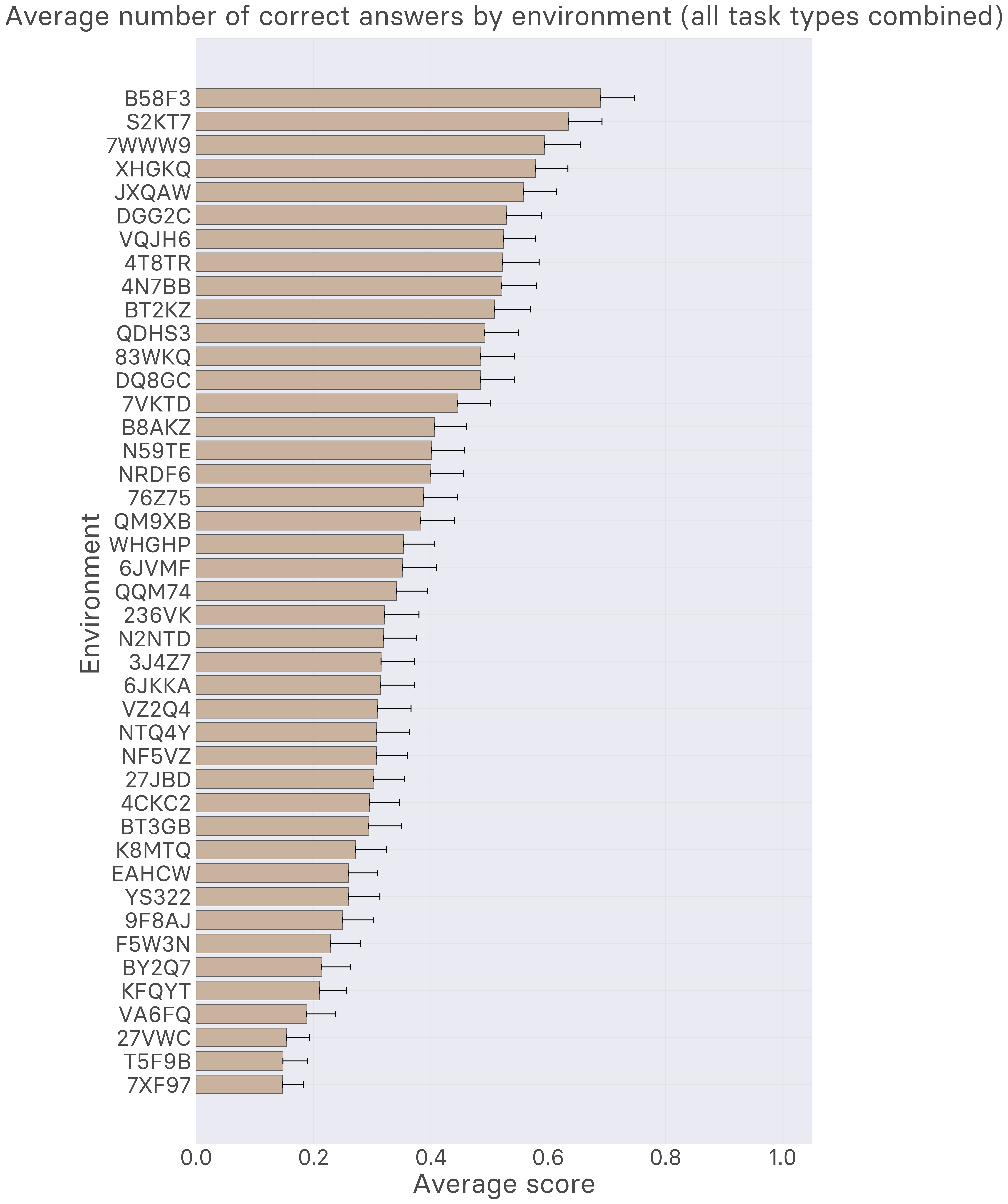
Environment-Specific Difficulty: Different AutumnBench environments pose varying levels of challenge, with some being accessible to most humans while others challenge even the best performers. The performance distribution shows clear differentiation between easier and harder tasks.
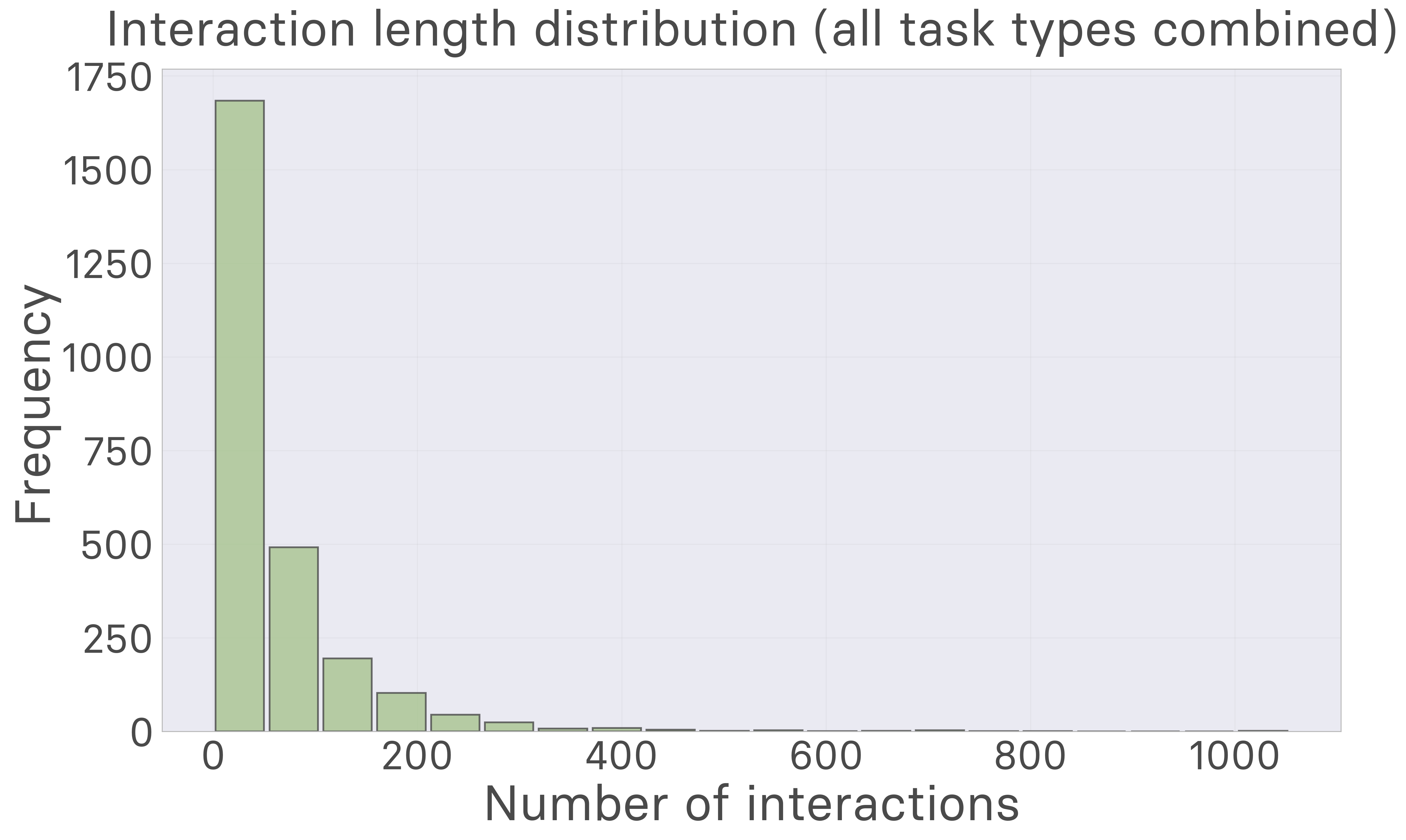
Interaction Patterns: Participants demonstrate systematic exploration patterns, with most taking 20-80 actions during the free experimentation phase. This suggests that effective world model learning requires substantial but not exhaustive interaction with the environment.
Key Behavioral Insights: Our analysis reveals several important patterns in how humans approach world model learning:
Task-Specific Adaptation: Humans calibrate their exploration behavior based on the anticipated evaluation type. When expecting to be tested on planning (which allows continued interaction), participants explore less intensively during the initial phase compared to prediction or change detection tasks.
Coverage vs. Performance: There’s a complex relationship between how much of the environment participants explore (coverage ratio) and their ultimate performance, suggesting that quality of exploration matters more than quantity.
Reset Behavior: Participants strategically use environment resets to test hypotheses and confirm their understanding, with more resets generally associated with better performance on complex tasks.
AI Performance Results
How do LLMs stack up on AutumnBench? We tested several frontier language models including Claude 4 Sonnet, Gemini 2.5 Pro, and o3, and find that they consistently underperform humans across all task types. Our analysis reveals fundamental limitations in how current AI systems approach world model learning through exploration and experimentation.
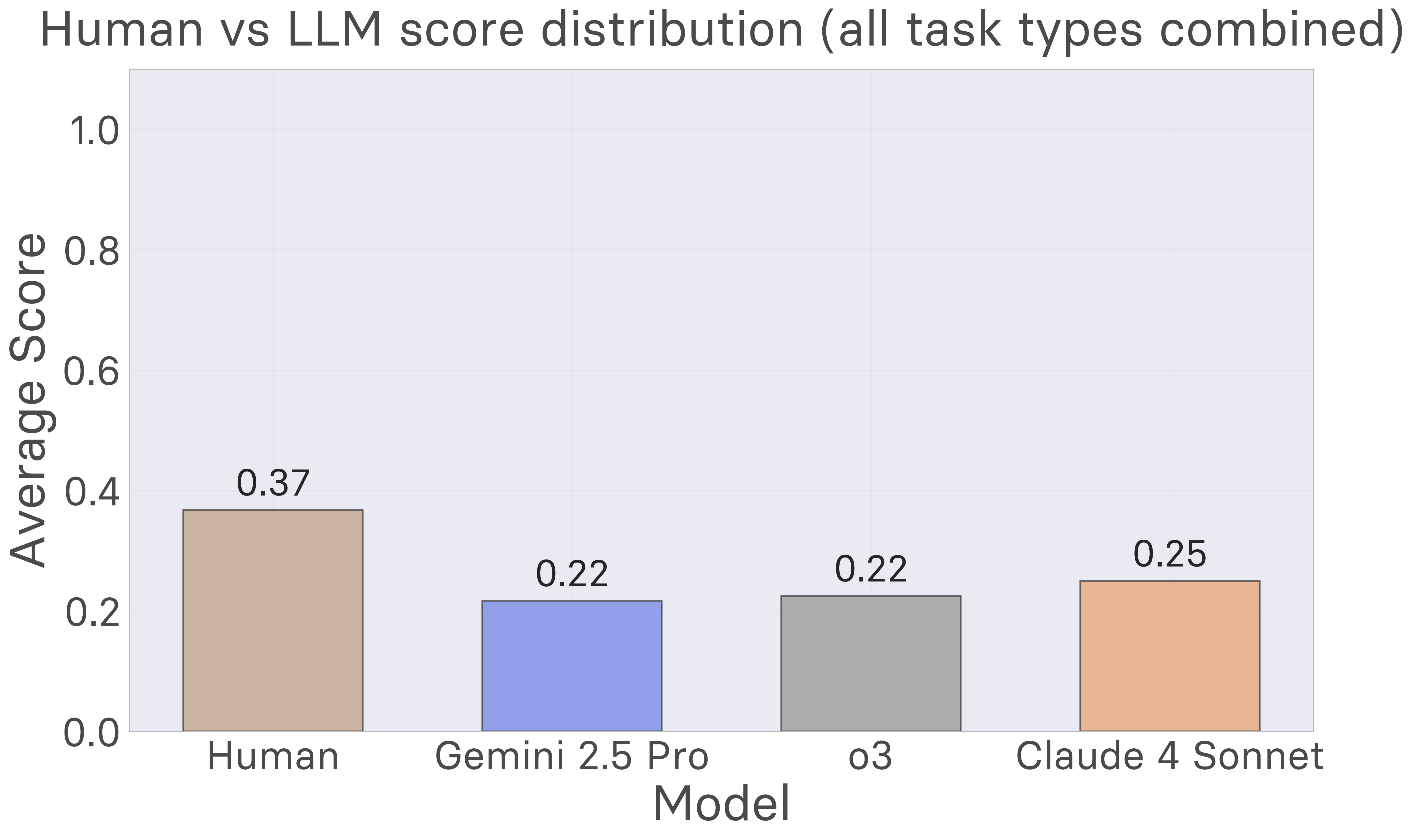
Task-Specific AI Performance
Masked Frame Prediction: LLMs show their strongest performance on masked frame prediction tasks, where the format resembles in-context learning scenarios these models excel at. However, even in this domain, they remain below human-level performance.
Planning Tasks: LLMs severely underperform humans on planning tasks, achieving significantly lower success rates when asked to reach target configurations. This aligns with known limitations of LLMs in sequential decision-making and planning domains.
Change Detection: Models struggle most with detecting when environment dynamics change, often failing to notice or correctly identify transition points that humans readily detect.
Model-Specific Analysis
Comparing different frontier models reveals consistent patterns of limitation:
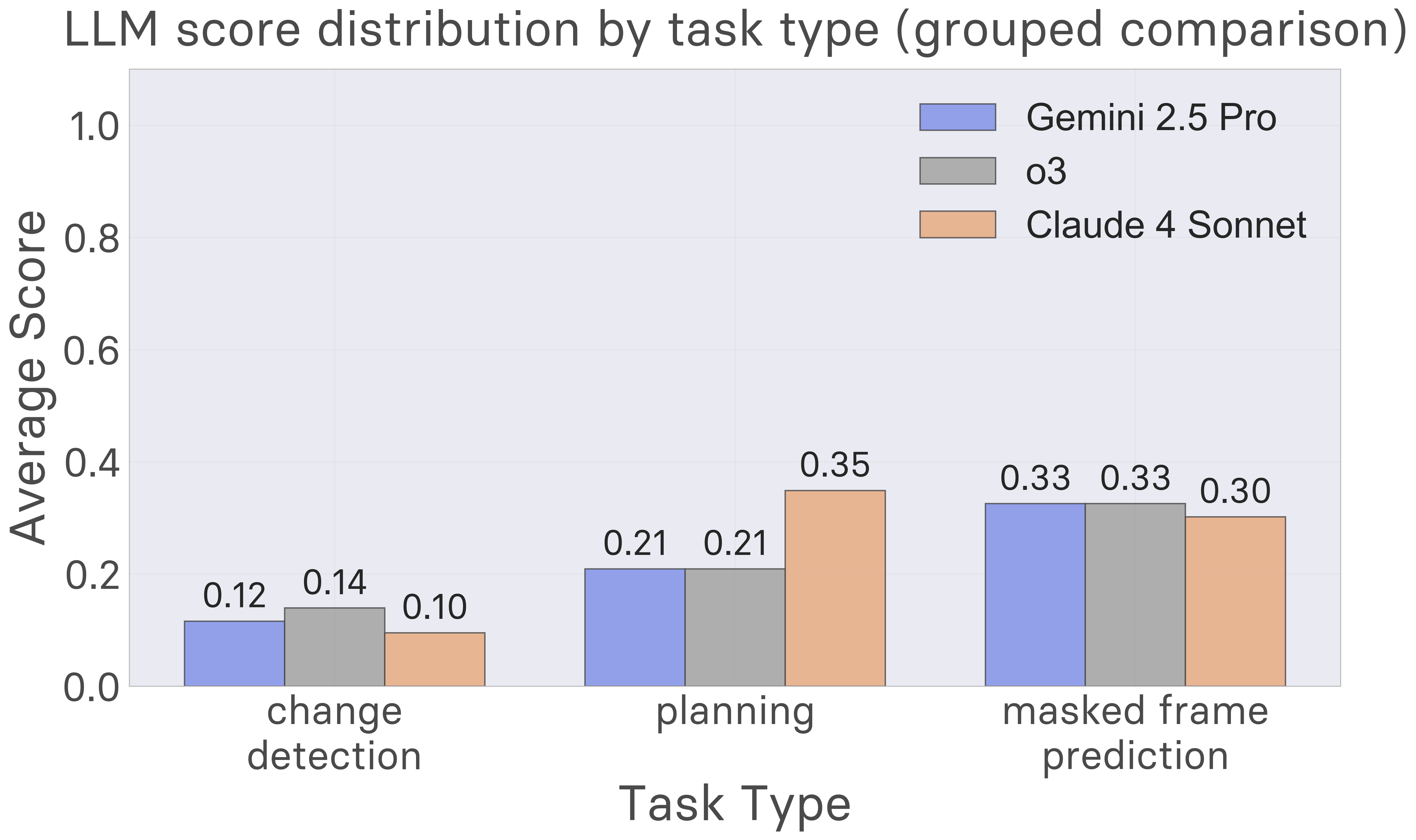
- Claude 4 Sonnet: Shows relatively balanced performance across task types but still falls short of human baselines.
- Gemini 2.5 Pro: Demonstrates similar overall patterns with slight variations in specific domains.
- o3: Surprisingly, switching to large reasoning models does not substantially improve planning performance, suggesting the limitation is not simply about computational depth but reflects fundamental challenges in world model learning.
While overall performance is similar across models, closer examination reveals interesting differences. For instance, as shown in the figure below, Claude substantially outperforms Gemini on planning tasks despite lagging marginally on prediction and change detection. We hypothesize that these differences reflect the distinct training priorities of model developers. Claude 4 Sonnet was post-trained with a focus on agentic coding workflows, which likely contributes to its stronger planning performance. As LLMs become specialized components of broader AI systems, we expect to see increasing divergence in task-specific capabilities.
Exploration and Interaction Patterns
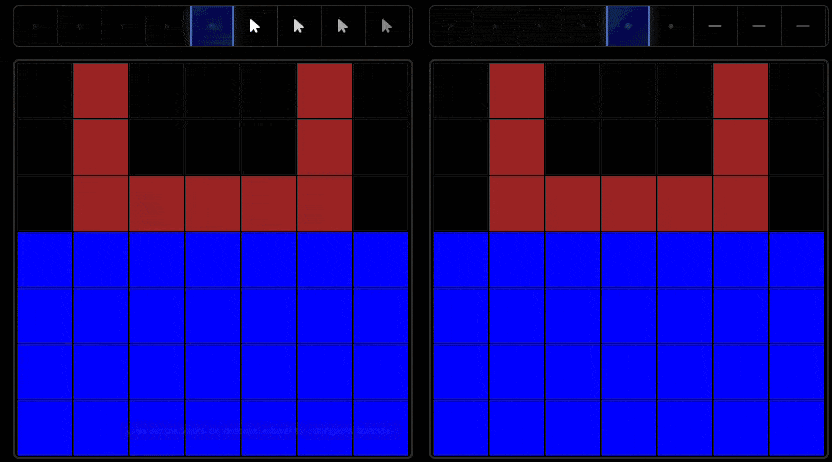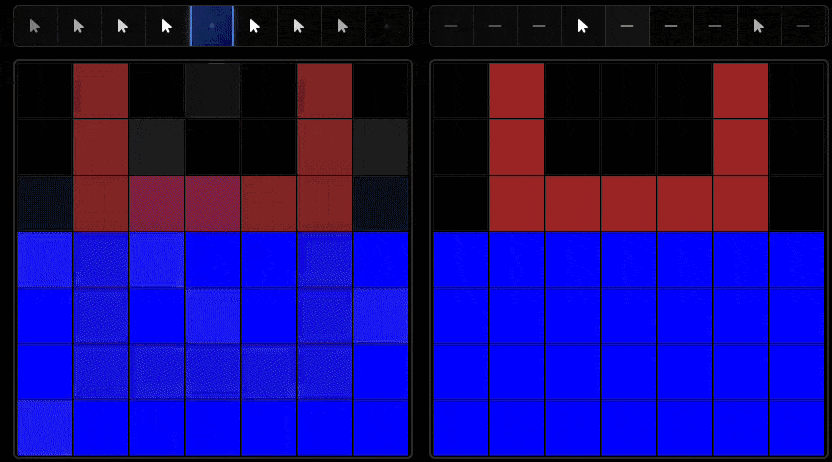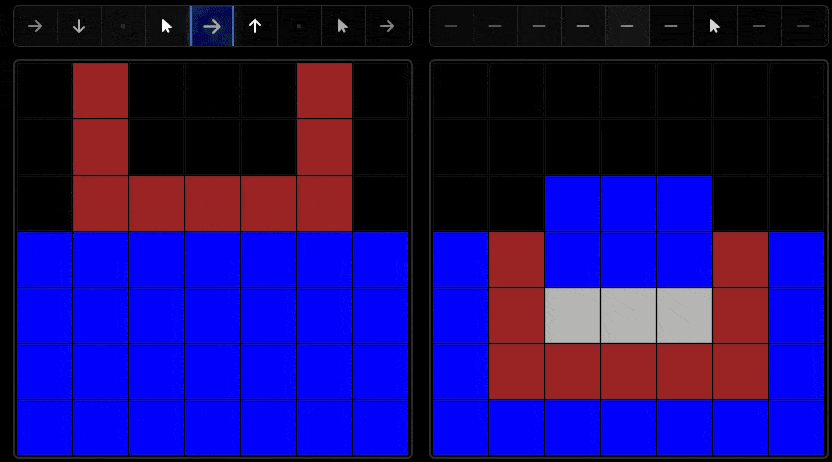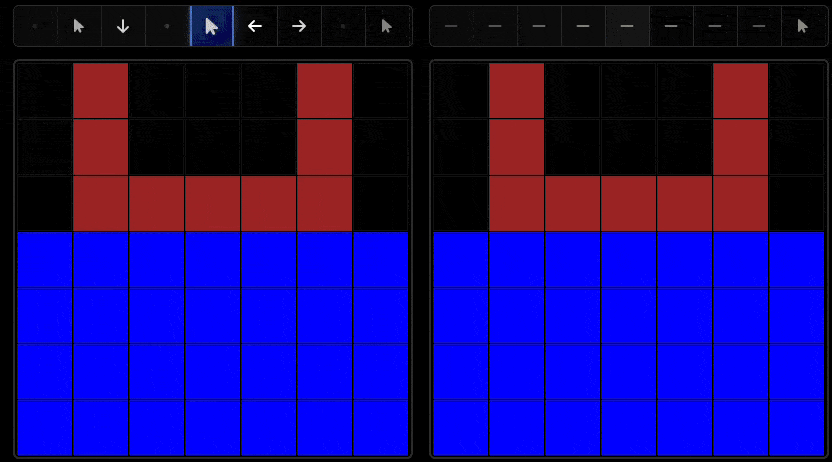
One key difference between humans and AI systems lies in their exploration behavior. While humans demonstrate systematic, hypothesis-driven exploration patterns, AI systems often exhibit less purposeful interaction strategies.
Human vs AI Comparison
The performance gap between humans and AI systems on AutumnBench is substantial and systematic:
- Overall Performance: While humans average 1.86/5, current LLMs achieve significantly lower scores across all task types.
- Exploration Behavior: AI systems often fail to explore environments systematically, missing crucial causal mechanisms during the free experimentation phase.
- Hypothesis Testing: Unlike humans who strategically use resets and targeted interactions to test hypotheses, AI systems show less purposeful exploration patterns.
- Task Transfer: Humans demonstrate better ability to apply insights from exploration to diverse reasoning tasks, while AI systems struggle to generalize their limited understanding.
What if the AI had a perfect world model?
AutumnBench has two phases: Free experimentation, followed by testing. The experimentation phase gives an opportunity to learn a world model. To isolate each phase, we build an agent which has access to the ground truth Autumn program for each environment, called the Oracle Baseline. It does breadth-first search to solve planning tasks, and runs the ground truth world model for change detection and prediction tasks.
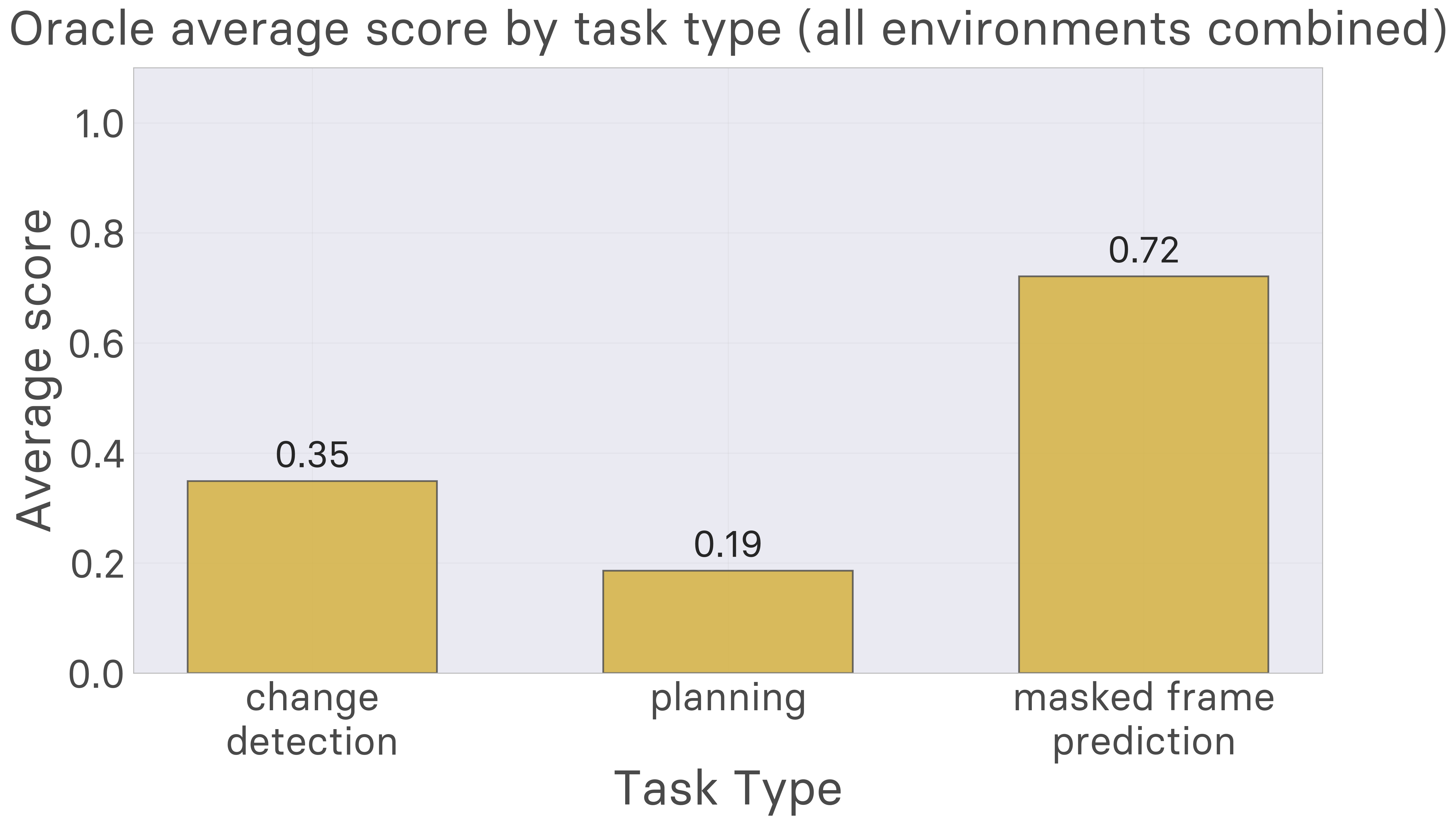
The oracle baseline excels at next-frame prediction and change detection, but struggles with planning. This is in stark contrast to the human data, which shows that planning success need not rely on perfect prediction. While recovering a world model equivalent to what the oracle has would be a useful next step, it does not seem to be what people are doing in these environments, and does not suffice for human-level performance, let alone going beyond what people can do.
Comparison to ARC-AGI-3
AutumnBench shares important design principles with the Abstraction and Reasoning Corpus (ARC), particularly the use of abstract grid worlds to mitigate reliance on prior knowledge. ARC-AGI-3, the successor to ARC, introduces interactive environments with abstract regularities. Compared to AutumnBench, both involve active learning within abstract environments, but there are important differences in approach and focus:
- Reward-free learning: In AutumnBench, the environments do not have a ‘win’ condition or external reward signal, and agents need to learn how the world works solely from intrinsic motivation. ARC-AGI-3 environments are presented as games in the style of reinforcement learning, which has the advantage of conforming to the typical agent setting, but the disadvantage of making the environments less open-ended.
- Transfer learning: Each AutumnBench environment is standalone, and is not organized into game levels. ARC-AGI-3 environments comprise a sequence of levels, which has the advantage of testing transfer learning by allowing agents to learn from simpler levels and reuse that knowledge later.
- World model learning vs. Game winning. AutumnBench is about learning how the world works, which we believe requires a battery of tests rather than a single win condition. ARC-AGI-3 focuses on learning to complete a series of levels, and so is a better benchmark of learning goal-directed behavior.
Code Release and Public Benchmark
We’re making AutumnBench fully open and accessible to the research community
- Autumn.Cpp: A Cpp implementation that compiles into WebAssembly, allowing AutumnBench to run in any modern browser.
- Benchmark Interface: A public web interface for testing AI systems and collecting human data.
- MARA Protocol Implementation: Complete tooling for running MARA-style experiments.
Getting Started
Researchers can immediately begin testing their systems on AutumnBench through our web interface at autumn.basis.ai. For automated evaluation of AI systems, we provide API access and template code for common model architectures.
Future Directions
We hope for AutumnBench to stimulate progress on automated world model building, and for the benchmark to grow to encompass both a wider variety of environments and a wider variety of types of tests, such as imputing the past, answering counterfactuals, describing how the world works in natural language, forming analogies between similar environments, and other kinds of of reasoning problems that a world model helps with.
However, the AutumnBench setup does not cover everything we would expect of a system capable of discovering how the world works through experimentation. Ultimately, we want systems that can interact with the real physical world in its full high-dimensional richness, which can interoperate with human experimenters, and which can perform everyday science in contexts such as robotics, and which could also provide principles for building AI scientists that could serve as collaborators for expert humans.
Contributors
Research: Archana Warrier, Dat Nguyen, Michelangelo Naim, Cambridge Yang, Moksh Jain, Yichao Liang, Karen Schroeder, Joshua Tenenbaum, Kevin Ellis, Zenna Tavares.
Acknowledgments: Ria Das for work on original Autumn, Julian Jara-Ettinger for feedback on the experimental design, Tobias Gerstenberg for feedback, Benjamin Crouzier and Tufa Labs for support and feedback, Mike Knoop, Francois Chollet, and Greg Kamradt for work on ARC and for engaging discussions.